GeoHash是一种地址编码,通过切分地图区域为小方块(切分次数越多,精度越高),它能把二维的经纬度编码成一维的字符串。也就是说,理论上geohash字符串表示的并不是一个点,而是一个矩形区域,只要矩形区域足够小,达到所需精度即可。
GeoHash特点
- 纬度和经度是二维的数据,建索引的时候需要对纬度和经度同时建索引,geohash 能将二维的数据转化为一维的数据,可以用B树等索引
- geohash 生成的字符串代表的不是地图上的一个点, 而是地图上一个矩形的区域,在一定程度上能保证隐私。
- 字符串越长,表示的范围能够更加的精确。 8位的geohash 编码的经度能达到19米左右,9位的geohash经度能达到米级,一般情况下能满足我们大部分的需求
- GeoHash值的前缀相同的位数越多,代表的位置越接近,可以方便索引。(反之不成立,位置接近的GeoHash值不一定相似)
- 方案的缺点是:从geohash的编码算法中可以看出,靠近每个方块边界两侧的点虽然十分接近,但所属的编码会完全不同。
GeoHash编码长度与精度的关系图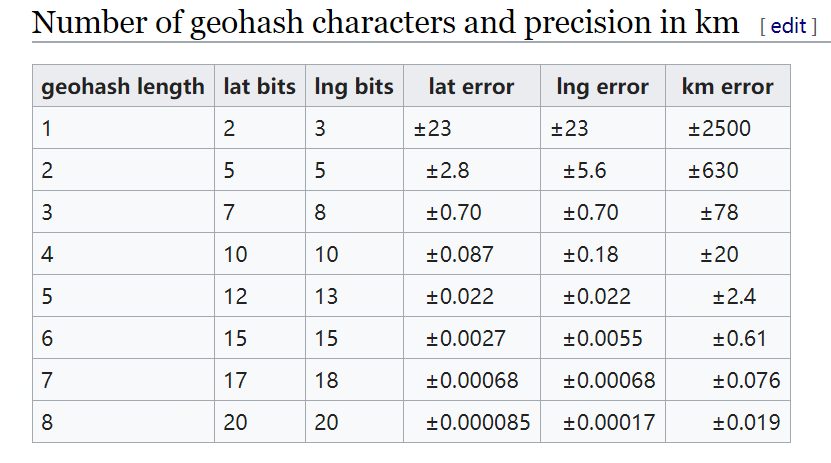
在下面会介绍Base32编码以5bits为一组,且在经纬度二进制码交叉组合时偶数位为经度、奇数位为纬度,所以上图中当geohash长度为1时,即只有5bits,因此5bits中包含3bits的经度值和2bits的纬度值。
GeoHash计算步骤
以杭州为例介绍GeoHash算法计算过程,杭州经纬度为(120.19,30.26)
根据经纬度计算GeoHash二进制编码
杭州经度为120.19,如果对地球经度范围进行一次划分,分为[-180,0)和[0,180]两个区间,则120.19属于区间[0,180],于是取编码1;然后再将[0, 180]分成 [0, 90), [90, 180]两个区间,而120.19位于[90, 180],所以编码为1。以此类推,直到精度符合要求为止。得到经度的二进制编码为11010101011101111110101111
编码过程如下图所示: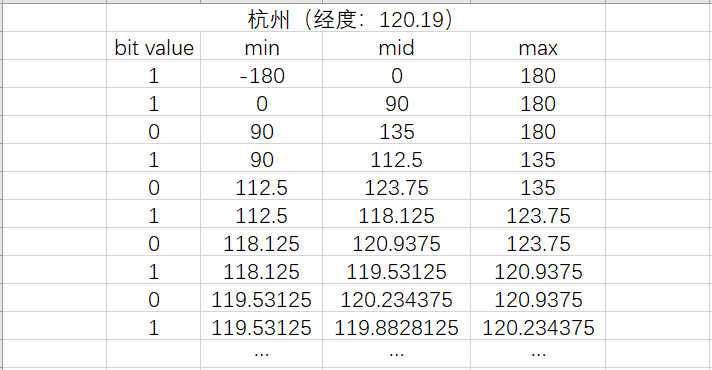
同理,地球纬度区间为[-90, 90],进行同样的划分可以得到纬度的二进制编码为10101011000010010101010001
将上述得到的经纬度二进制编码交叉进行组合,偶数位放经度,奇数位放纬度,把2串编码组合生成新串:1110011001100111001010100110101110111001100110101011(注意:是交叉进行组合,而不是简单地直接放纬度编码拼接在经度编码后面)
二进制编码进行Base32编码
Base32编码,是将数字 0~9 ,加上26个字母(去除a,i,l,o 四个)总共32个字符进行组合而成的编码形式。数字与编码字符对应关系如下图所示: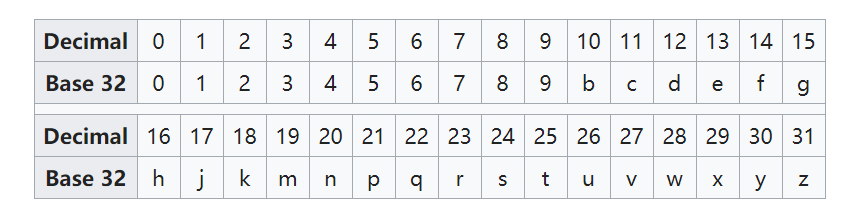
然后将获取到的经纬度二进制数以每5个数为一组,将每一组都进行转换成十进制数字。然后采用Base32对应编码进行转换可得到编码wtmknuxtmb0。比如我们的经纬度都分了10次,那么最后生成的字符串的长度就是4,范围是20km,如果我们经纬度都分20次,那么最后生成的字符串的长度就是8,范围可以精确到19m。
杭州地理位置Base32编码示意图:
GeoHash算法原理
上文讲了GeoHash的计算步骤,仅仅说明是什么而没有说明为什么?为什么分别给经度和维度编码?为什么需要将经纬度两串编码交叉组合成一串编码?
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,经度左半区间为0,右半区间为1,纬度下半区间 为0,上半区间为1,于是经纬度二进制编码交叉组合,得到编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子块也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
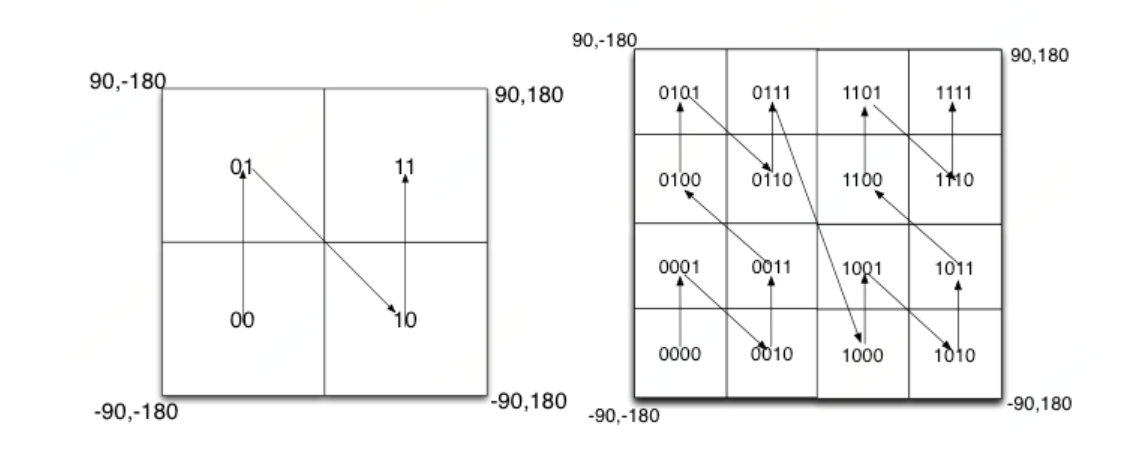
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
边界问题
上面也说了,这个算法看起来完美,但是稍微也有点问题,就是有些编码相邻但距离却相差很远,有些地理位置相对较近,却编码并不相邻。那么该怎么找出这些位置相近而编码不相邻的位置呢?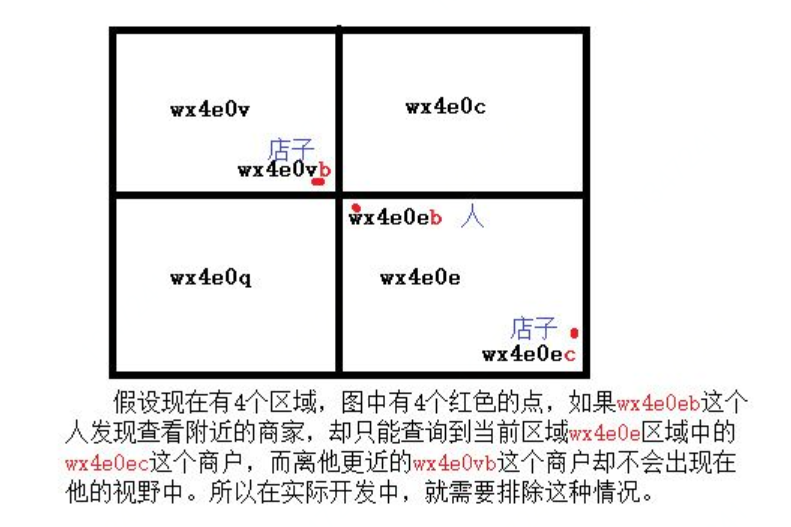
按照单个区域情况考虑,就会出现如上所示的情况。所以就得想办法解决这种情况,就需要将范围进一步扩大。
目前比较通行的做法就是我们不仅获取当前我们所在的矩形区域,还获取周围8个矩形块中的点。那么怎样定位周围8个点呢?关键就是需要获取周围8个点的经纬度,那我们已经知道自己的经纬度,只需要用自己的经纬度减去最小划分单位的经纬度就行。因为我们知道经纬度的范围,有知道需要划分的次数,所以很容易就能计算出最小划分单位的经纬度。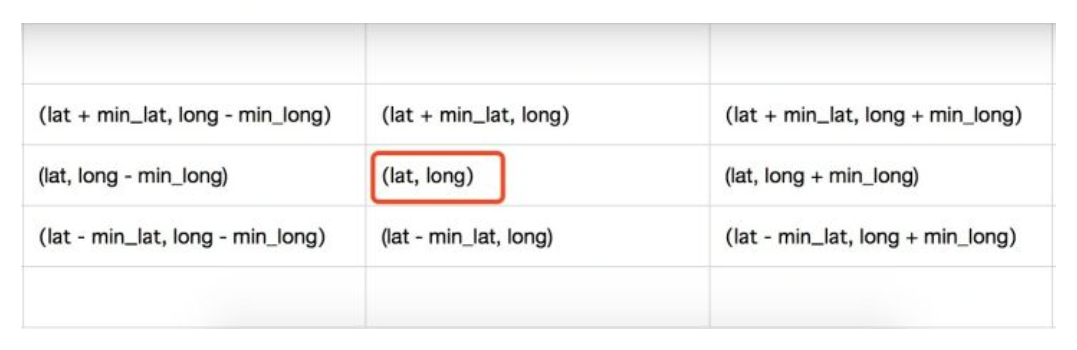
通过上面这张图,我们就能很容易的计算出周围8个点的经纬度了。有了经纬度就能定位到周围8个矩形块了。这样我们就能获取包括自己所在矩形块的9个矩形块中的所有的点。最后分别计算这些点和自己的距离(由于范围很小,点的数量就也很少,计算量就很少)过滤掉不满足条件的点就行了。
在redis中,查找某个中心地理位置(longitude,latitude)周围radius范围内的点,先根据latitude和radius计算出经纬度二进制编码的长度step,即划分的次数,然后根据中心地理位置(longitude,latitude)、radius、step计算出中心位置的二进制编码,再计算出周边8个位置块的二进制编码,再依次计算9个位置块中的点是否满足距离要求。
GeoHash算法实现
GeoHash算法实现,这里主要展示redis中的实现方式:
typedef struct {
double min;
double max;
} GeoHashRange;
typedef struct {
uint64_t bits;
uint8_t step;
} GeoHashBits;
int geohashEncode(const GeoHashRange *long_range, const GeoHashRange *lat_range,
double longitude, double latitude, uint8_t step,
GeoHashBits *hash) {
/* Check basic arguments sanity. */
if (hash == NULL || step > 32 || step == 0 ||
RANGEPISZERO(lat_range) || RANGEPISZERO(long_range)) return 0;
/* Return an error when trying to index outside the supported
* constraints. */
if (longitude > 180 || longitude < -180 ||
latitude > 85.05112878 || latitude < -85.05112878) return 0;
hash->bits = 0;
hash->step = step;
if (latitude < lat_range->min || latitude > lat_range->max ||
longitude < long_range->min || longitude > long_range->max) {
return 0;
}
double lat_offset =
(latitude - lat_range->min) / (lat_range->max - lat_range->min);
double long_offset =
(longitude - long_range->min) / (long_range->max - long_range->min);
/* convert to fixed point based on the step size */
lat_offset *= (1ULL << step);
long_offset *= (1ULL << step);
hash->bits = interleave64(lat_offset, long_offset);
return 1;
}
long_range和lat_range为地球经纬度的范围;hash->bits用户保存最终二进制编码结果,hash->step是经纬度划分的次数,在redis中该值为26,即经度/纬度的二进制编码长度为26,最终经交叉组合而成的地理位置的二进制编码为52位。Base32编码为每5bits组成一个字符,所以最终的GeoHash字符串为11位。
为什么是52位?因为在redis中是把地理位置编码后的二进制值存入zset数据结构中,double类型的尾数部分长度为52位。
上述算法在分别计算经度/纬度的二进制编码时,是先计算所求地理位置的经度/纬度在整个经度/纬度范围内的偏移,再乘以2的step次方。划分step次,会得到2的step次方个区域,区域值为0-(1<<step-1),所以偏移乘以2的step次方即可得到划分step次时改经度/纬度的二进制编码。
下面以杭州经度二进制编码计算过程示意图如下,计算划分三次的情况下的编码: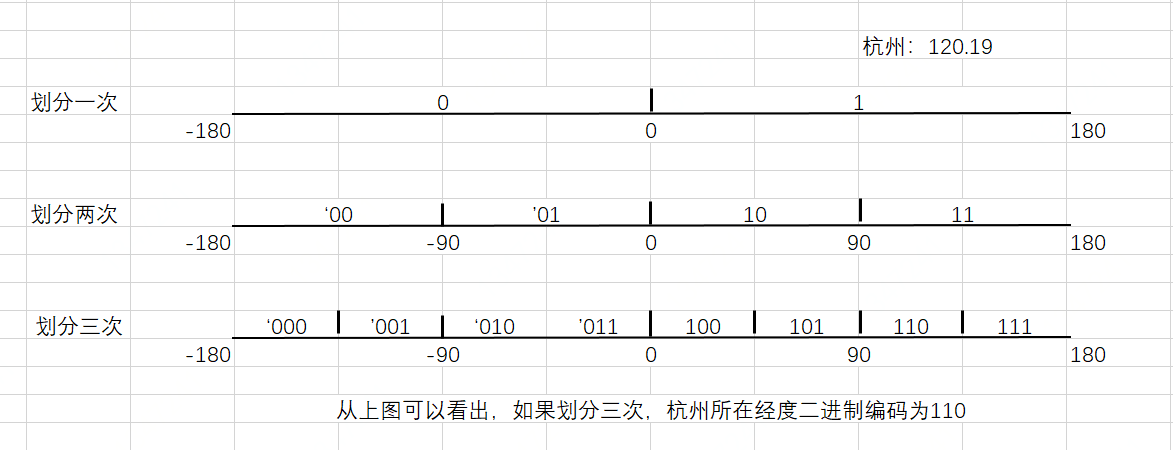
如上图所示,经度120.19在划分三次情况下的编码为110,等于 (120-(-180))/(180-(-180))*(1<<3)
interleave64函数用于实现交叉组合经纬度的二进制编码,偶数位为经度,奇数位为纬度,改算法见stanford大学一个网站,该网页上有很多巧妙的位操作实现。算法实现如下所示:
/* Interleave lower bits of x and y, so the bits of x
* are in the even positions and bits from y in the odd;
* x and y must initially be less than 2**32 (65536).
* From: https://graphics.stanford.edu/~seander/bithacks.html#InterleaveBMN
*/
static inline uint64_t interleave64(uint32_t xlo, uint32_t ylo) {
static const uint64_t B[] = {0x5555555555555555ULL, 0x3333333333333333ULL,
0x0F0F0F0F0F0F0F0FULL, 0x00FF00FF00FF00FFULL,
0x0000FFFF0000FFFFULL};
static const unsigned int S[] = {1, 2, 4, 8, 16};
uint64_t x = xlo;
uint64_t y = ylo;
x = (x | (x << S[4])) & B[4];
y = (y | (y << S[4])) & B[4];
x = (x | (x << S[3])) & B[3];
y = (y | (y << S[3])) & B[3];
x = (x | (x << S[2])) & B[2];
y = (y | (y << S[2])) & B[2];
x = (x | (x << S[1])) & B[1];
y = (y | (y << S[1])) & B[1];
x = (x | (x << S[0])) & B[0];
y = (y | (y << S[0])) & B[0];
return x | (y << 1);
}